


Transformer des mots en chiffres - Comment les ordinateurs comprennent-ils le langage humain ?
C'est la rentrée pour Infografix, et il est impossible de passer à côté de l'engouement actuel pour les intelligences artificielles comme ChatGPT. En particulier, OpenAI vient de sortir son nouveau modèle o1, présenté comme capable de réfléchir (si vous lisez l'anglais, je vous recommande la lecture de ce rapport). Ces modèles de langage impressionnent par leur capacité à converser, rédiger des textes cohérents et parfois même par leur capacité à réfléchir.
Mais comment une machine, qui, dans le fond, ne connaît que des suites de 0 et de 1, peut-elle saisir la complexité et la richesse des mots que nous utilisons au quotidien ?
Aujourd'hui, j'ai eu envie d'explorer un peu plus la manière dont les ordinateurs parviennent à manipuler notre langage, voire à le comprendre.
Je vous propose de plonger ensemble dans ce fascinant sujet. Pas de panique, nous avancerons pas à pas pour démystifier tout cela.
Des mots, des chiffres et des vecteurs
Les ordinateurs sont des machines logiques, excellant dans le traitement de données structurées et numériques. Le langage humain, en revanche, est plein de nuances, d'ambiguïtés et de contextes culturels. Pour permettre aux machines de traiter le langage de manière efficace, il a fallu trouver un moyen de représenter les mots sous une forme mathématique qu'un ordinateur peut manipuler.
La solution réside dans la conversion des mots en vecteurs numériques, une technique appelée word embedding.
En mathématiques, un vecteur est généralement représenté par une flèche avec une magnitude (taille) et une direction. Par exemple, dans un espace tridimensionnel, un vecteur est décrit par trois chiffres, par exemple : [4, 2, 7].
Mais de manière plus générale, un vecteur est simplement une liste de nombres, avec autant d’éléments que nécessaire.
Dans notre contexte, chaque nombre contenu dans le vecteur va représenter une caractéristique d'un mot.
Exemple avec des mots simples
Prenons trois mots simples : "chat," "chien," et "poisson". Nous pouvons décrire chaque mot en utilisant quelques caractéristiques :
Caractéristique 1 : À quel point le mot est lié à "un animal de compagnie".
Caractéristique 2 : À quel point le mot est lié à "être petit".
Caractéristique 3 : À quel point le mot est lié à "vivre dans l'eau".
Nous pouvons créer un vecteur pour chaque mot :
- "chat" pourrait être [0.9, 0.8, 0]
- "chien" pourrait être [0.9, 0.5, 0]
- "poisson" pourrait être [0.1, 0.9, 0.97]
Dans le cadre que nous nous sommes fixé, ces vecteurs signifient :
- "Chat" est à 90% un animal de compagnie, 80% petit, et 0% vivant dans l'eau.
- "Chien" est à 90% un animal de compagnie, 50% petit, et 0% vivant dans l'eau.
- "Poisson" est à 10% un animal de compagnie, 90% petit, et 97% vivant dans l'eau.
Ces exemples sont assez arbitraires et simplifiés, mais ils illustrent comment le sens d’un mot peut être encodé sous forme de vecteur. Ce qui est intéressant ici, c’est que les mots ne sont pas décrits par leur définition stricte, mais plutôt par des concepts qui leur sont associés.
Imaginez maintenant qu’au lieu de trois caractéristiques, nous en utilisions des milliers. Par exemple, le mot "chat" pourrait être lié à des concepts comme "pattes", "doux", "poil", "câlin", "indépendant", "griffes", "vif," "félin", etc. Le vecteur associé au mot "chat" inclurait des relations pondérées avec des milliers d’autres mots.
La construction de ces vecteurs de plusieurs milliers de valeurs ne peut pas être réalisée à la main. Cette tâche est plutôt confiée à des algorithmes qui "apprennent" à partir de grandes quantités de texte. Ces algorithmes analysent la manière dont les mots coapparaissent dans les phrases pour pondérer chaque relation entre les mots. Dans un certain sens, ces algorithmes permettent de construire des modèles qui ont une compréhension des relations sémantiques et des régles de language.
Le principe fondamental est que les mots qui apparaissent dans des contextes similaires ont des significations similaires.
Par exemple :
- "Chat" et "chien" apparaissent souvent dans des contextes similaires ("Le chat/chien dort", "Le chat/chien court", "Carresser le chat/chien" etc.).
- Les vecteurs associés à "chat" et "chien" seront donc proches dans l'espace vectoriel.
Cette proximité permet aux modèles de comprendre que ces mots sont liés sémantiquement.
Pourquoi les vecteurs sont-ils importants dans ce contexte ?
Les vecteurs deviennent vraiment intéressants quand on se souvient de nos cours d’algèbre linéaire et de la possibilité de réaliser des opérations avec eux.
Vous savez sans doute qu’il est possible d’ajouter ou de soustraire des vecteurs en deux dimensions. Eh bien, le même principe s’applique dans un espace à 3, 10, 1000, ou "n" dimensions. Pour rappel, un mot peut être défini par une serie de milliers de nombres, c'est à dire un vecteur dans un espace qui comprend des miliers de dimensions.
Par conséquent, avec des mots encodés sous forme de vecteurs, on peut effectuer ce genre d’opérations :
vecteur("roi") - vecteur("homme") + vecteur("femme")
Si les vecteurs ont été bien construits, autrement dit, s'ils capturent efficacement la sémantique des mots, le résultat de cette opération donnera un vecteur très proche de celui du mot reine . Dans notre espace vectoriel, on a donc :
vecteur("roi") - vecteur("homme") + vecteur("femme") ≈ vecteur("reine")
Je le répète, mais ce qui est fascinant ici, c’est que les vecteurs permettent de capturer le sens des mots, et de les combiner pour les lier à d'autres mots et d'autres concepts plus complexes.
En représentant les mots dans un espace vectoriel multidimensionnel, les modèles parviennent à saisir les subtilités du sens et les relations entre les mots.
Bien, à ce stade on a vu les concepts de base de la vectorisation des mots. On est quand même encore loin de modèle de language comme ChatGPT.
Mais avant d'aller plus loin, j’aimerais vous montrer que, l’encodage des mots sous forme de vecteurs a déjà des applications pratiques.
Grâce à ces techniques, on peut par exemple analyser rapidement de grandes quantités de texte, en repérant des relations entre les mots, les concepts ou les thématiques. Cela peut permettre d'automatiser des tâches qui seraient autrement complexes et chronophages.
Une application concrète : améliorer les soins en maison de retraite
Pour illustrer l'impact réel de la transformation des mots en vecteurs, prenons l'exemple d'une étude récente intitulée "Text Mining in Long-Term Care: Exploring the Usefulness of Artificial Intelligence in a Nursing Home Setting", un article de C.Hacking et al., 2022 que l'on peut traduire par "Exploration de texte dans les soins de longue durée : Exploration de l'utilité de l'intelligence artificielle dans une maison de retraite".
Qu'est ce qu'ils on fait dans cette étude ?
Les chercheurs ont d'abord collecté des données en réunissant les commentaires et les entretiens des résidents et des familles sous forme de textes. Chaque mot et chaque phrase ont ensuite été transformés en vecteurs, capturant ainsi leur signification et leur contexte.
En regroupant les vecteurs similaires (c'est à dire proches dans l'espace multidimensionnel), ils ont pu identifier des thèmes récurrents comme la "qualité des repas", la "propreté" ou les "interactions sociales". Cette étape, appelée analyse thématique, permet de faire ressortir les sujets les plus importants pour les personnes concernées.
De plus, l'utilisation des vecteurs a permis d'effectuer une analyse de sentiment, déterminant si les commentaires étaient positifs, négatifs ou neutres. Cela offre une vision plus nuancée des perceptions des résidents et du personnel.
Grâce à cette approche, l'étude a permis d'identifier clairement les points forts et les faiblesses des établissements. Par exemple, elle a mis en évidence les domaines nécessitant des améliorations, comme la qualité des repas ou le besoin de davantage d'activités sociales.
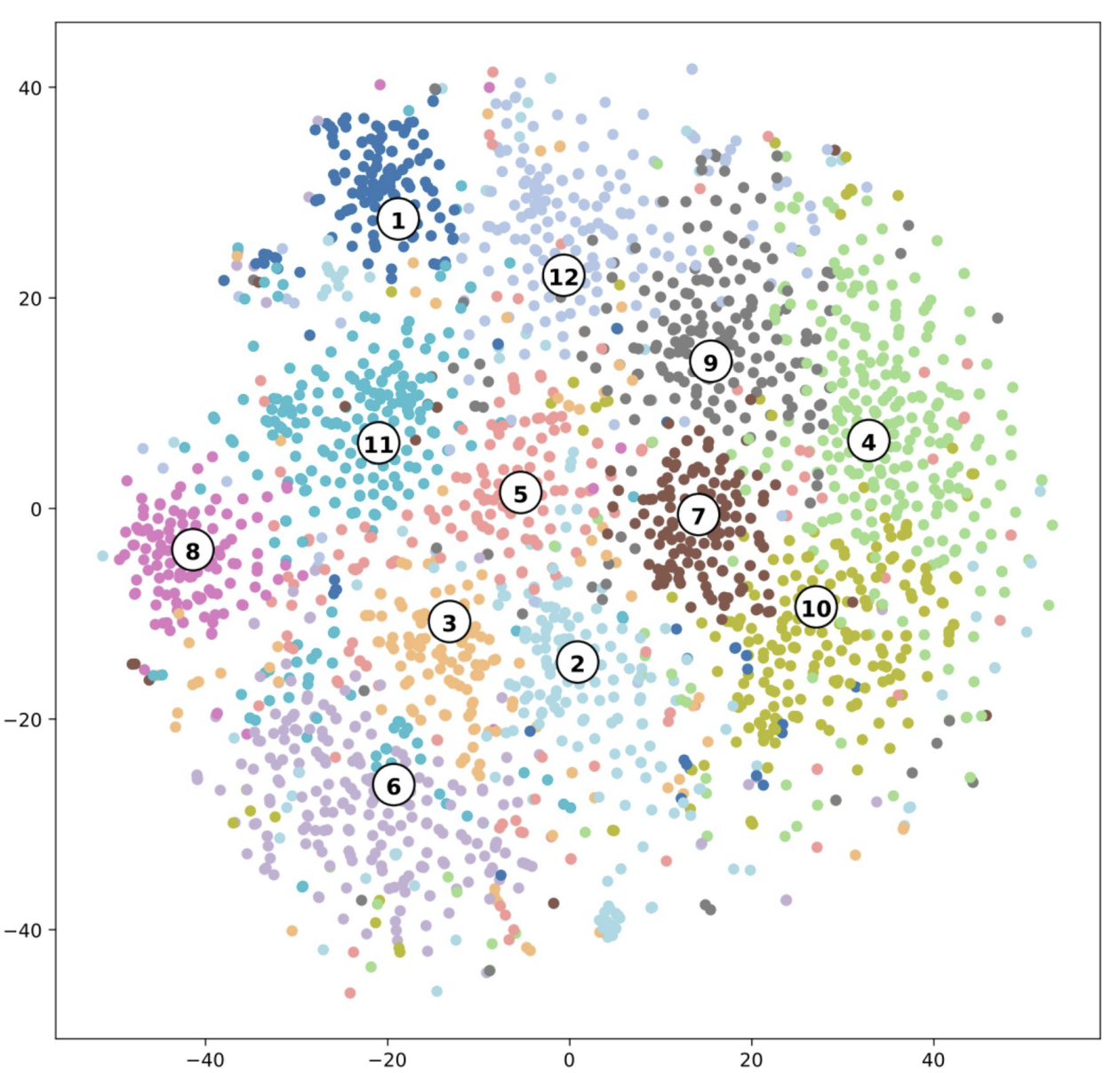
Sur cette figure, l'analyse de regroupement thématique est représentée de manière visuelle. Chaque point sur le graphique correspond à un mot-clé ou une phrase extrait des entretiens. Les points qui sont proches les uns des autres indiquent que ces mots ou phrases sont sémantiquement liés et appartiennent au même thème.
Les différentes couleurs distinguent les 12 thèmes identifiés dans l'étude, tels que "relations", "environnement de soins" ou "santé". Les numéros associés aux clusters font référence aux noms des thèmes listés dans le tableau suivant :
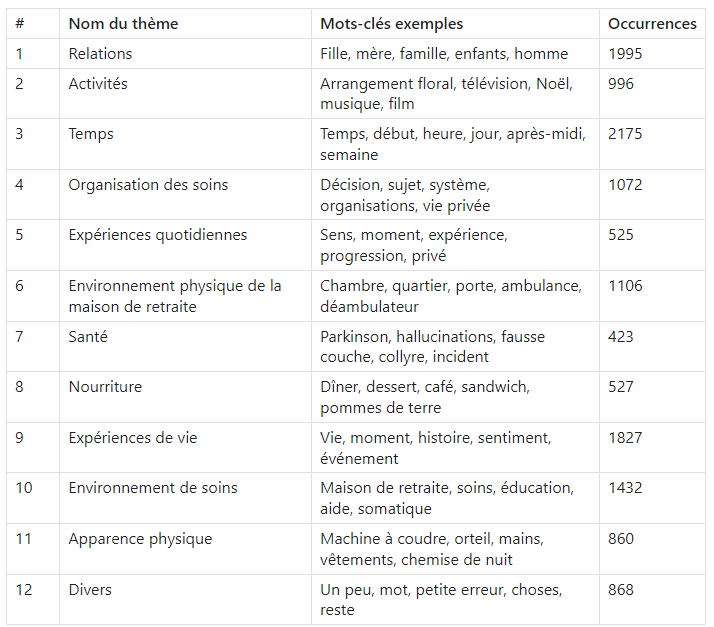
Cette visualisation, et le tableau avec les occurences offrent un moyen organisé de comprendre des données narratives complexes. Cette étude illustre comment l'analyse de texte à grande echelle peut révéler des thèmes et des sujets importants.
L'objectif final est d'aider à prioriser les axes d'amélioration de la maison de retraite étudiée.
Bien, revenons au début de notre petite histoire : On a vu comment les ordinateurs, grâce à l'utilisation de vecteurs, peuvent capturer les relations sémantiques entre les mots. On a vu aussi une utilisation concrète de ces outils avec l'exemple de la maison de retraite.
J'ai le regret de vous annoncer que, même si nous avons bien avancé, nous n'avons gratté qu'une fine croûte à la surface d'un énorme gâteau. Il reste plein de concepts à explorer. Les modèles de langage qui nous impressionnent tant utilisent d'autres couches techniques pour prendre en compte le contexte des mots, leur place dans la phrase, pour générer du texte, pour conserver une trace de la conversation en cours etc.
Mais c'est un sujet qui va au-delà du cadre de cet article et que nous explorerons certainement dans une autre édition !




Comments